What is it?
Reqstool generates reports and updates on progression of requirement implementations and testing by reading data specified in several *.yml files.
In order to use the reqstool, you will need to create a requirements.yml file along with a software_verification_cases.yml and/or a manual_verification_results.yml.
How it works
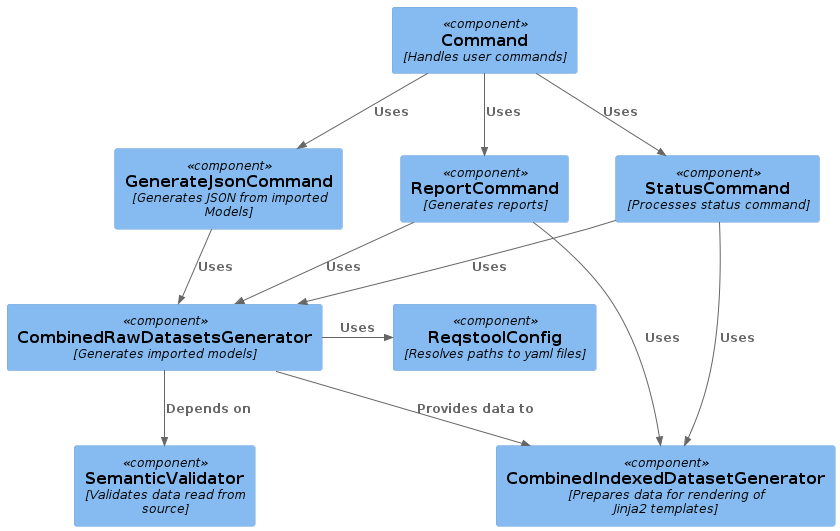
All of the commands available for the user requires an argument specifying a path to where Reqstool should start to look for the required files. When a valid path is provided, the CombinedRawDatasetsGenerator component parses all yaml files in the specified path and validates the generated content with the SemanticValidator component. The -h command of the application can assist you regarding what argument you’ll need to provide for each command.
What each command actually does is described under usage
Resolve custom paths
If you are providing a path to a git repository or a Maven artifact, you can override the reqstool_config.yml[default locations] of the yaml files by providing a requirements_config.yml file in the same folder as your requirements.yml. In the requirements_config.yml, you are able to describe the structure of your repository/artifact and specify where the required yaml files are located. If the CombinedRawDatasetsGenerator detects such a file, it will try to locate the required files from the path described in the requirements_config.yml instead of the default path using the ReqstoolConfig component.
What is validated?
The SemanticValidator makes sure that the data within the yaml files is as correct as possible. If any errors are found, it prints a summary of them to stdout. This is a convenience for the user so that they can detect errors in their yaml files and correct them quickly.
The main things that are validated is:
-
No duplicate Requirement/SVC/MVR id’s.
-
SVC’s refers to Requirements that actually exists
-
Annotation implementations refers to existing Requirements
-
Annotation tests refers to existing SVC’s
-
MVR’s refers to existing SVC’s
-
SVC’s and Requirements has only one of the import/exclude filters set per file
Template generation
The CombinedIndexedDatasetGenerator prepares the data provided from the CombinedRawDatasetsGenerator for rendering with the Jinja2 templates and is used of the ReportCommand and the StatusCommand components.
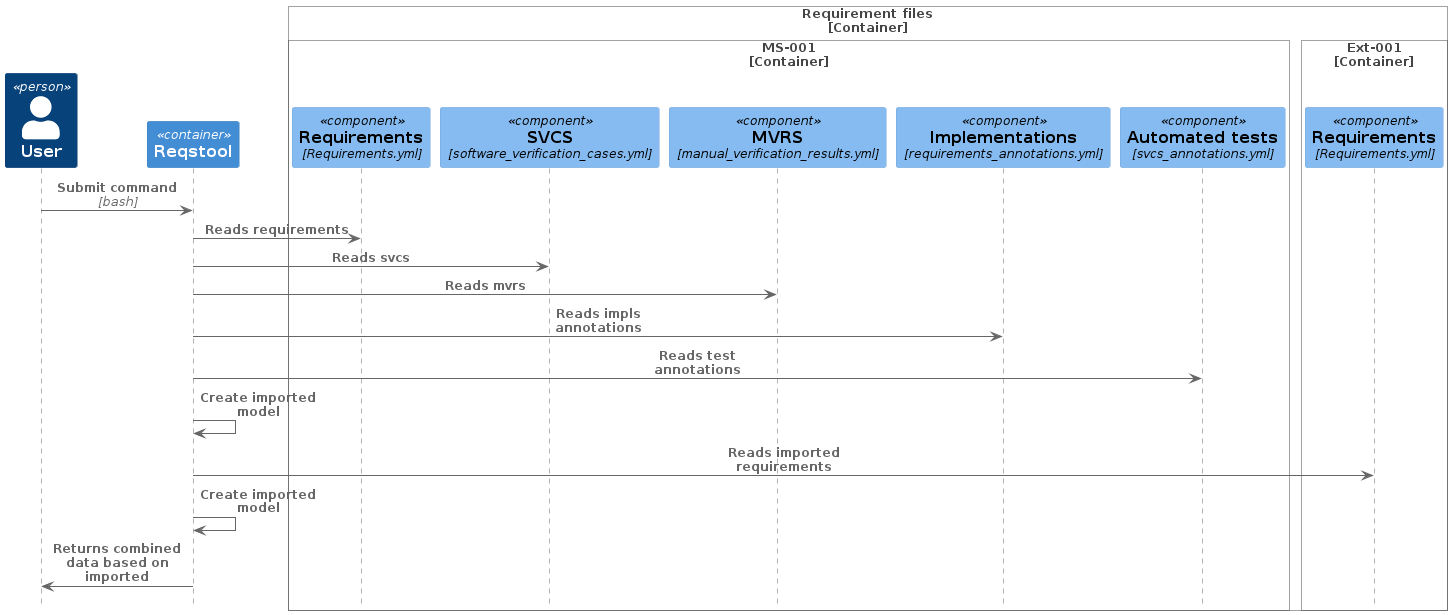
How parsing is done
If data is retrieved from multiple sources, the parsing begins sequentially from the URI the user provides, and this becomes the initial source of the Reqstool report. So, if you have a micro service (let’s call i ms-001) that will also inherit requirements from another source (ext-001), you want to start the parsing in the docs/requirements path of ms-001
When the initial source’s requirement file are processed, Reqstool will then continue to parse the other sources that are specified within the import parameter of the initial source’s requirement file. If filters is applied in the initial source, the data in the following sources will adhere to these settings.
For example, if you want to exclude one requirement from ext-001, then you specify it like this in the requirements.yml file in ms-001 project:
imports:
local:
- path: ./ext-001
filters:
ext-001:
requirement_ids:
excludes:
- REQ_101When Requirement Tool is reading the data from ext-001, then REQ_101 will not be imported in the returning data, but all other requirements specified in ext-001’s requirements.yml file will.
Filters can currently be applied to requirements.yml and software_verification_cases.yml.